1. Introduction
The VLBA department at the University of Oldenburg is responsible for the implementation and administration of storage and High-Performance Computing (HPC) infrastructure. This includes the deployment of HEAppE, staging workers, the LEXIS platform, and the iRODS zone, along with S3-compliant data stores. The deployment of these components will optimize data management, ensure seamless data transfer, and facilitate efficient computational workflows.
2. Key Components
2.1 HEAppE Middleware Deployment
HEAppE (High-End Application Execution Platform) is a crucial middleware component that enables secure job execution on HPC clusters by providing an API-based interface for job submission and monitoring. It is designed to integrate seamlessly with HPC systems, allowing users and applications to interact with computational resources efficiently.
Key Features of HEAppE:
- Job Submission and Management: Users can submit, monitor, and manage computational jobs remotely through the HEAppE API.
- Secure Authentication and Authorization: Supports multiple authentication mechanisms, including SSH keys, Kerberos, and OAuth tokens.
- Integration with HPC Schedulers: Compatible with Slurm, PBS, and other batch scheduling systems for efficient resource allocation.
- Scalability and Flexibility: Allows deployment on cloud or on-premise HPC clusters with customizable configurations.
- Monitoring and Logging: Provides real-time tracking of job performance and system metrics using tools like Grafana and Node Exporter.
Deployment Considerations:
- HEAppE should be installed first as the primary middleware component before integrating with other storage and computing services.
- Proper authentication setup between HEAppE and the HPC cluster is required to ensure secure job execution.
- System administrators must configure HEAppE to interact with the chosen batch scheduler to streamline job processing.
- Performance monitoring tools should be deployed alongside HEAppE to track resource usage and provide insights for optimization.
2.2 Staging Worker and iRODS Zone
If storage is available, it is recommended that partners set up a staging worker and an iRODS zone:
- Staging Worker: This is an instance of a Celery worker connected to PostgreSQL and RabbitMQ, responsible for transferring data between storage systems and computing resources.
- iRODS Zone: Provides efficient handling of data across multiple locations by abstracting physical data storage systems into datasets and collection.
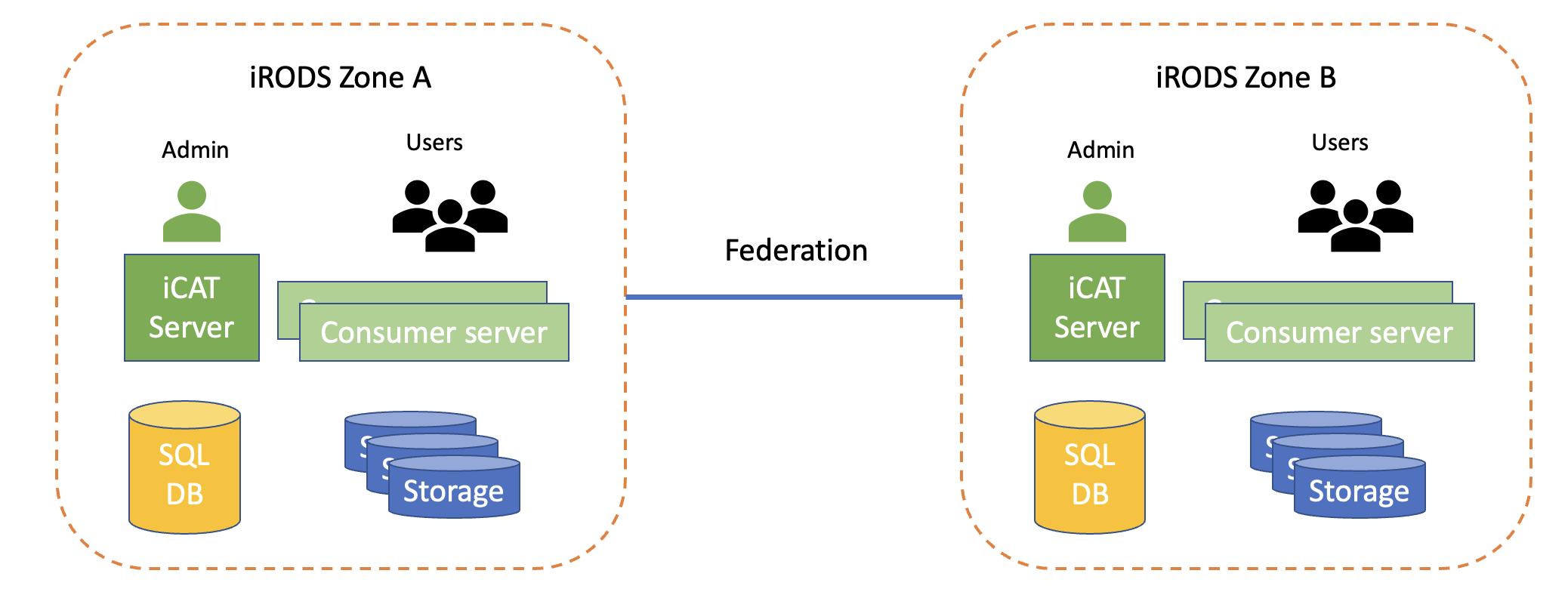
Both components optimize data flow, reduce latency, and ensure data is readily available for computational tasks.
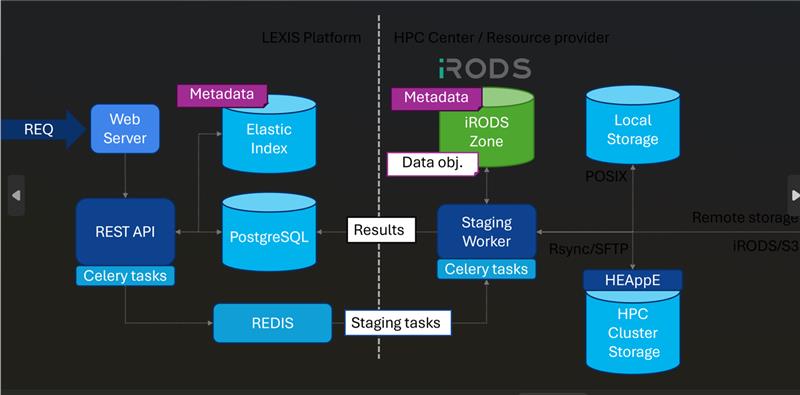
2.3 LEXIS Platform
The LEXIS platform enables automated workflows across cloud and HPC systems, providing:
- HPC-as-a-Service functionality
- Integrated cloud and HPC computing systems
- Workflow orchestration
- Automated big data management
- Identity and access management
- Secure data upload and download
3. Monitoring and Logging
To ensure optimal system performance and troubleshoot potential issues, the following monitoring and logging tools should be implemented:
-
Grafana: A visualization tool that provides real-time dashboards to monitor system performance, including CPU, memory, and network usage.
-
Node Exporter: Collects hardware and operating system metrics, integrating seamlessly with Prometheus for further analysis.
-
Checkmk: A comprehensive monitoring system that enables proactive identification of performance bottlenecks and system health issues.
-
Logging Frameworks: Centralized logging solutions should be deployed to capture logs from all components, allowing for efficient debugging and system auditing.
By deploying these tools, administrators can track resource utilization, ensure system stability, and generate reports for performance analysis.